


当前深度学习模型已经发展得非常复杂,如Xception有2100万参数,带有BN 层的VGG11有2850万参数需要训练,更遑论最近推出的新模型的参数量已达到不可思议的地步(如GPT-3拥有1700亿参数)。而相对而言,即使是被认为数据量足够的自然图像,其训练样本数在庞大的参数面前也显得不足,例如,大规模数据集ImageNet也“仅”包含1400万张图片。为何深度学习在正常数据上没有出现严重的过拟合现象,但在随机拟合、对抗攻击中又表现的极其脆弱?这些反常的现象一直困扰着深度学习的理论研究者。同时,巨量的神经网络参数的训练也对环境带来了压力。据报道,世界上600个最大的训练中心/集群用于神经网络的耗电量自2012年以来已经增长了3000倍,目前已相当于5000万美国家庭用电量之和。因此,发现神经网络的低维结构、发展环境友好的训练算法具有重大的理论和现实意义。
神经正切核(NTK:Neural Tangent Kernel)是近年兴起的分析神经网络动态特性的有效工具。对于输入为![]() ,参数
,参数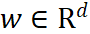 的神经网络
的神经网络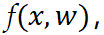
其在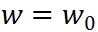 处的 NTK 定义为
处的 NTK 定义为
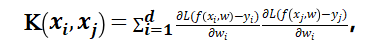
其中,![]() 为损失函数,
为损失函数,![]() 为标签。在一些假设条件(过参数化、LeCun初始化,SGD训练等)下,可以证明NTK在训练中是稳定的并且将训练轨迹刻画为:
为标签。在一些假设条件(过参数化、LeCun初始化,SGD训练等)下,可以证明NTK在训练中是稳定的并且将训练轨迹刻画为:

其中,![]() 为初始神经网络,
为初始神经网络,![]() 为最优神经网络,t 为迭代步数,
为最优神经网络,t 为迭代步数,
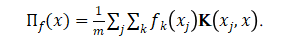
受启发于在训练中NTK保持不变、参数轨迹符合常微分方程的解等现象,上海交通大学黄晓霖团队发现神经网络在动态过程中展现出很好的线性性质,可以利用NTK的低秩特性对其进行近似,并将神经网络动态行为描述为:
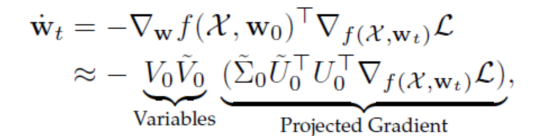
其中,![]() 。注意到后面几项构成了一个维
。注意到后面几项构成了一个维 ![]() 向量,由此可以得到神经网络的动态超低维结构,并且:
向量,由此可以得到神经网络的动态超低维结构,并且:
深度神经网络的高维参数向量的训练轨迹可以被低维向量所涵盖
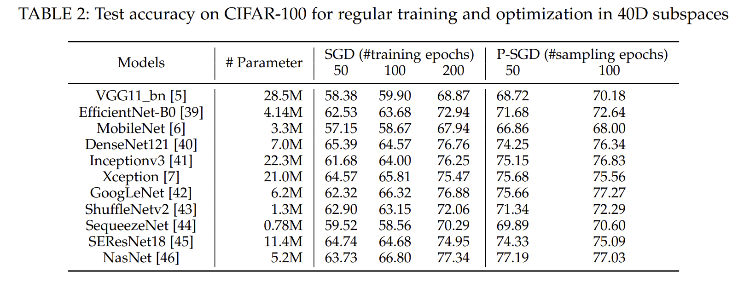
超低维结构是否存在的金标准在于,是否确实可以通过优化 ![]() 维向量达到优化 n 维向量的效果。基于超低维结构猜想及NTK所表明的降维方法,黄晓霖团队设计了利用动态轨迹的神经网络参数降维方法,并在低维空间对网络进行训练。在CIFAR-10/CIFAR-100级别任务中,在多个标准网络的实验表明,可以在40维空间,达到几乎与全空间训练(几百万甚至千万维)一致的效果,由此证实了神经网络的训练动态中确实存在着低维结构,并且其低维的程度超乎一般的想像。具体的维度与网络结构、具体任务、数据情况相关。如团队与华为中央媒体研究院一起在200维空间进行训练达到百万级参数的训练效果并将算法在华为Mindspore和昇腾训练平台上发布。
维向量达到优化 n 维向量的效果。基于超低维结构猜想及NTK所表明的降维方法,黄晓霖团队设计了利用动态轨迹的神经网络参数降维方法,并在低维空间对网络进行训练。在CIFAR-10/CIFAR-100级别任务中,在多个标准网络的实验表明,可以在40维空间,达到几乎与全空间训练(几百万甚至千万维)一致的效果,由此证实了神经网络的训练动态中确实存在着低维结构,并且其低维的程度超乎一般的想像。具体的维度与网络结构、具体任务、数据情况相关。如团队与华为中央媒体研究院一起在200维空间进行训练达到百万级参数的训练效果并将算法在华为Mindspore和昇腾训练平台上发布。
论文链接:https://arxiv.org/abs/2103.11154v2 https://arxiv.org/abs/2111.12229v1
